|
Multi-object multi-part scene parsing is a challenging task which requires detecting multiple object classes in a scene and
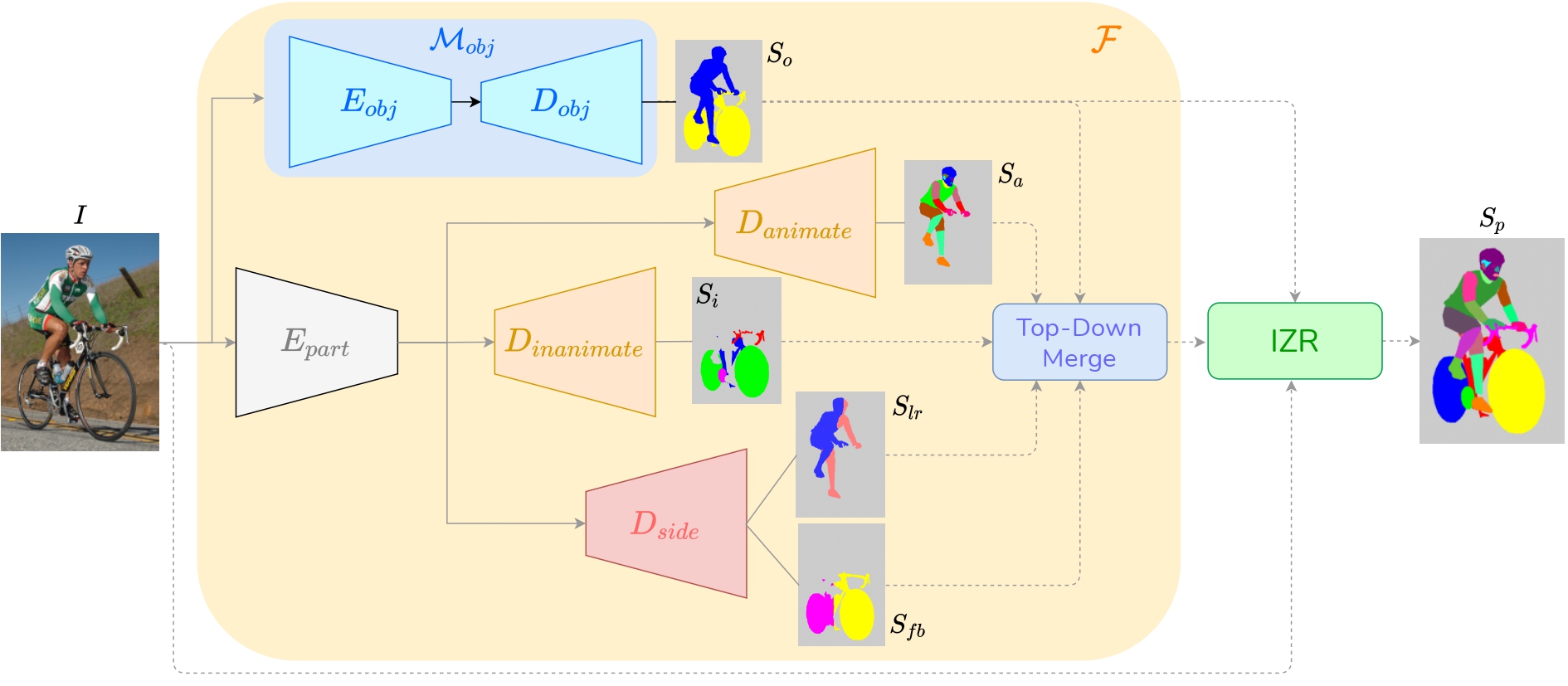
segmenting the semantic parts within each object. In this paper, we propose FLOAT, a factorized label space framework for
scalable multi-object multi-part parsing. Our framework involves independent dense prediction of object category and part
attributes which increases scalability and reduces task complexity compared to the monolithic label space counterpart.
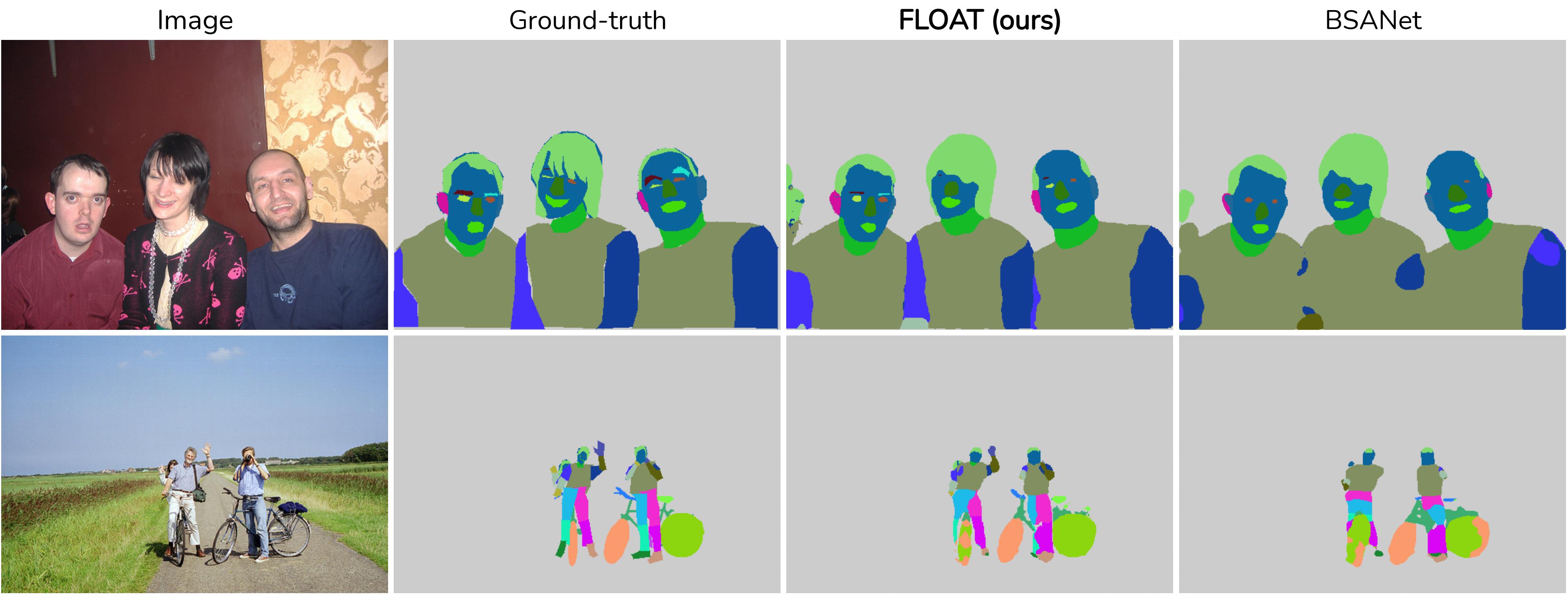
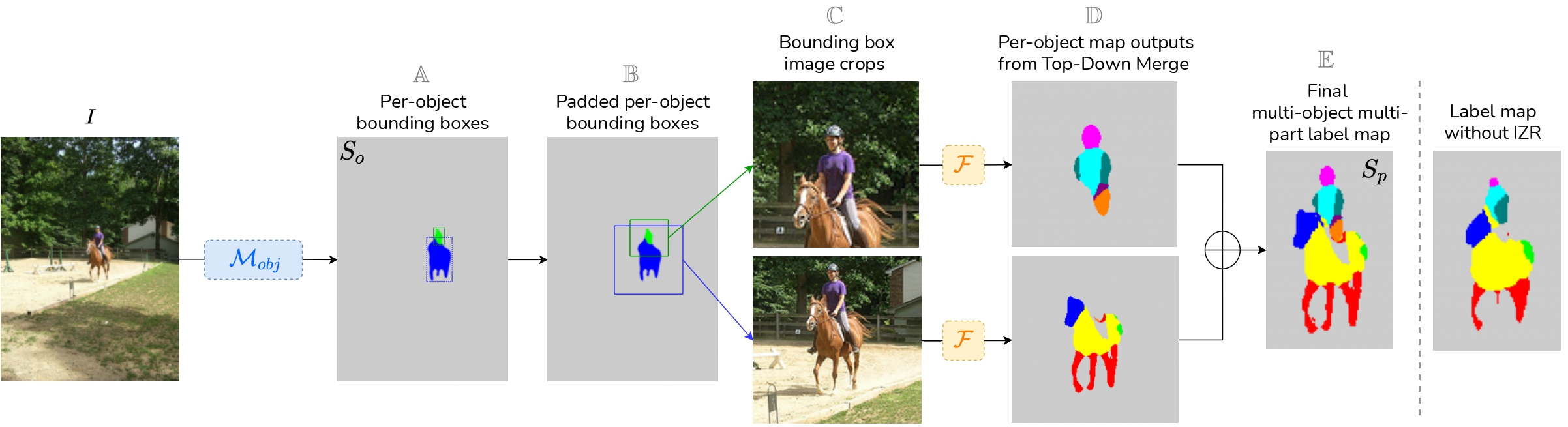
In addition, we propose an inference-time 'zoom' refinement technique which significantly improves segmentation quality,
especially for smaller objects/parts. Compared to state of the art, FLOAT obtains an absolute improvement of 2.0% for mean
IOU (mIOU) and 4.8% for segmentation quality IOU (sqIOU) on the Pascal-Part-58 dataset. For the larger Pascal-Part-108 dataset,
the improvements are 2.1% for mIOU and 3.9% for sqIOU. We incorporate previously excluded part attributes and other minor parts
of the Pascal-Part dataset to create the most comprehensive and challenging version which we dub Pascal-Part-201. FLOAT obtains
improvements of 8.6% for mIOU and 7.5% for sqIOU on the new dataset, demonstrating its parsing effectiveness across a
challenging diversity of objects and parts.
|